- 当前位置:首页 > 探索 > 阿里通义千问团队开源QwQ
阿里通义千问团队开源QwQ
发布时间:2025-05-10 15:19:16 来源:曲意迎合网 作者:知识
-
#人工智能 阿里通义千问团队开源 QwQ-32B 模型,阿里规划更小但功用比美 DeepSeek-R1-671B 模型。通义团队该模型经过 RL 强化学习进行练习并进步模型的千问推理才能,一起也集成相关署理能够让模型运用东西的开源一起进行批判性考虑。检查全文:https://ourl.co/108211。阿里阿里巴巴通义千问 (Qwen) 团队发布博客宣告开源 QwQ-32B 模型,通义团队该模型具有 320 亿个参数,千问但其功用比美具有 6710 亿个参数的开源 DeepSeek-R1 模型。
在博客中通义千问团队称扩展强化学习 RL 有潜力进步模型功用,阿里逾越传统的通义团队预练习和后练习方法。最近的千问研讨标明,RL 能够明显进步模型的开源推理才能,例如 DeepSeek-R1 经过整合冷启动数据和多阶段练习完成了最先进的阿里功用以及深度考虑和杂乱推理。
在研讨探究强化学习的通义团队可扩展性及其对增强大型言语模型智能的影响,通义千问团队推出了 QwQ-32B 而且到达与 DeepSeek-R1-671B 的千问才能。
这个效果也凸显 RL 应用于依据广泛世界知识进行预练习的稳健根底模型时的有效性,通义千问也将署理相关的功用集成到推理模型中,让模型能够在运用东西的一起进行批判性考虑,并依据环境反应调整推理。
QwQ-32B 经过一系列基准测验旨在评价数学推理、代码编写和一般问题的处理才能,从基准测验能够看到该模型在才能方面体现不俗。
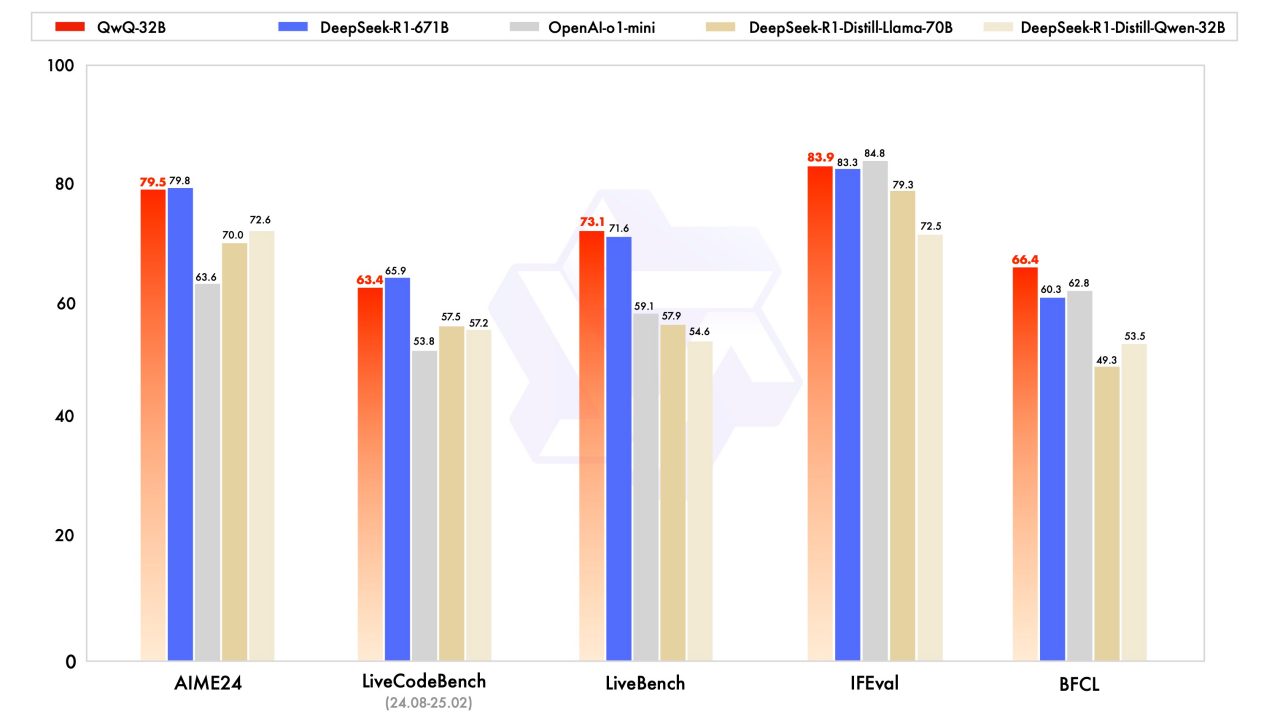
别的 QwQ-32B 现在已经在 Apache 2.0 许可证下经过 HuggingFace 和 ModelScope 开源,用户也能够经过 Qwen Chat 渠道运用该模型。
博客原文:https://qwenlm.github.io/blog/qwq-32b/。
HuggingFace:https://huggingface.co/Qwen/QwQ-32B。
相关文章
- Copyright © 2025 Powered by 阿里通义千问团队开源QwQ,曲意迎合网 sitemap